How are Databases Represented on Disk
Where do disk based database systems store data?
DBMS stores a database as one or more files on disk typically in a proprietary format. A file is a sequence of records (usually of the same type). The OS is responsible for storing the files on top of the existing file system and is not aware of the specifics of the file.
Why are the contents of the DBMS files proprietary?
The format of the file is proprietary to each DBMS since they are optimized to improve performance specific to the database. There are also some non-proprietary formats like Apache Parquet, ORC which are mainly used for big data applications.
What are the different files in which DBMS data and their related properties reside?
Data resides in Primary Files.
Index to the data which act as signpost or aid to locate them on storage device are saved in index files.
What are the different Primary File Organization techniques?
There are different file organization techniques, which determine how the data is stored and accessed by a DBMS
- Heap file (unsorted file) - stores the record on disk in no particular format by appending to the end of the file
- Sorted file - the data is stored in sorted order based on some fields (sorted key)
- Hashed file - some of the record's fields are used to determine its hash, which is then used to decide its location.
- B-trees - n-ary tree structures are used to store the records
Which layer is responsible for maintaining the database files?
The storage manager is responsible for maintaining a database's file. It is responsible for where the files are located (what the directory hierarchy is). Storage managers can have their own dispatchers to control whether to do sequential or random read
How does the storage manager organize a database file?
The database files are organized into pages. The storage manager is responsible for maintaining the status of the files, which includes keeping track of which files are being read or written. It is also responsible for maintaining the available space in the pages and performing timely compaction to reclaim free spaces.
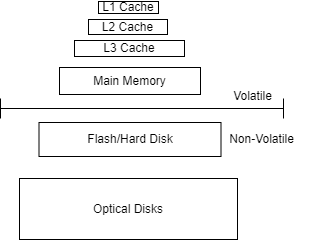
Is a file one continuous chuck of memory?
A file is stored in a hard disk which is comprised of blocks. A block is the lowest unit of memory that can be read from/written to disk. A file is divided into blocks on a hard disk.
How are files allocated organized on disk?
- A file can be stored on disk as a sequence of contiguous blocks. This makes reads faster since the next block to be read is located adjacent to the current block. The disk does not have to do a seek to locate the next block. However, this approach restricts the size of the file. If there are no more empty blocks present at the end of the last block then the whole file will have to be re-written to a new location.

- The blocks of files can also be arranged in linked fashion when one block contains the pointer to the next block. Though the writes do not have to concern about empty blocks being available contiguous to the last block, the reads become slower. Each new block read may result in disk seek thereby increasing the read latency.

- The cluster approach combines the above two by saving a segment of the file in continuous disk block (clusters) and saving the link to the next cluster in last block of the segment.

- The OS might also maintain separate blocks (index blocks) for maintaining the pointers (index) to the file block

The DBMSs usually use a combination of all these approaches.
Resources
- Database Internals - by Alex Petrov
- Database Storage Lecture - Andy Pavlo
- Fundamentals of Database Systems 6th Edition -Ramez Elmasri, Shamkant B. Navathe
Comments
Post a Comment